可爱的可并堆的一些扯淡
strcmp
·
·
算法·理论
前言
咋没有补的坑越来越多了。
本文一定程度上基于 WC2024 lxl 的讲义。
感觉现在看什么数据结构都很可爱。
希望有事实性错误的话有人指出。
计划
斜堆、随机堆、左偏树、配对堆、二项堆、Rank Paring Heap(赋级配对堆,秩对堆)、Fibonacci Heap(斐波那契堆)、斜二项堆、基数堆。
如果有能力的话学学 Brodal Queue(但感觉大概率没能力)。
还有一些神堆,可能要二次更新才会提到:
Strict Fibonacci Heap(基于比较的 GOAT)
Atomic Heap(ds 最高堆,线性整数 MST 和最短路)
以及一些关于持久化可并堆的东西。
还会放一些题目。
对 OI 相关性较低的东西可能会视情况减少篇幅以及延后更新,比如非常复杂的时间复杂度分析。
目前延后更新的内容:斜二项堆、基数堆的扩展、一些更多的题目和应用。并且视情况会加上一些难证复杂度的东西的证明。
维护操作
-
部分持久化: 我们维护的历史版本组成一个序列,我们每次只能在序列的末尾进行修改,然后修改的数据结构接在序列的末尾。
-
完全持久化: 我们维护的历史版本组成一棵有根树,我们每次可以在任意一个结点的基础上,继承它然后修改并成为它的儿子。
-
可合并持久化: 我们维护的历史版本组成一张 DAG,每次可以选取多个结点作为前驱并把它们合并组成一个新的历史版本,或者选取一个结点作为前驱并修改。
可以看到上述三个持久化形式的强度依次递增。
以下默认堆是小根的,因为改为大根堆是容易的。
一般来说,可并堆要支持的操作有以下几种:
-
push 插入一个值。
-
pop 删除最小值。
-
top 查询最小值。
-
merge 合并两个堆。
-
如果可以,那么支持 decrease key,也就是减小某个元素的值。
-
显然我们如果支持了 decrease key 就可以支持 delete,把要删除的元素置为 -\infty 然后 pop 即可。
-
如果可以,需要我们希望能够部分持久化、完全持久化或者可合并持久化。
基于比较的堆在构造数据下,进行 \Theta(n) 次 push 和对应次数的 pop 的复杂度不可能低于 \Theta(n \log n),因为这是基于比较排序的时间复杂度下界。当然有不基于比较的堆(比如基数堆)。
目前最优的复杂度是 Brodal Queue。做到严格非均摊的 \Theta(1) 的 push、top、merge 和 decrease key。只有 pop 是 \Theta(\log n) 的。
但是持久化的 Brodal Queue 无法支持 decrease key。
应用:n 个点 m 条边的弱连通图,Dijkstra 会进行 \Theta(n) 次 push 和 \Theta(n) 次 pop,但是会进行 \Theta(m) 次 decrease key。如果 decrease key 的复杂度做到 \Theta(1),则我们可以用 \Theta(n \log n + m) 的复杂度完成 Dijkstra 算法。
对 Prim 算法的优化类似。
\huge\textbf{DS}
先说一些比较平凡的东西。
一般的二叉堆利用启发式合并,得到均摊复杂度 \Theta(n \log^2 n) 的合并,而且除了 top 其它操作的复杂度都是 \Theta(\log n)。
直接使用 Finger Search 的平衡树即可做到均摊 \Theta(n \log n) 的合并。并且不改变其它操作的复杂度。在 OI 范围内,对 Treap 进行修改或者直接使用 Splay 即可做到。
当然因为启发式合并基于均摊,如果要持久化,上述的方法并不总是能用。
某种意义上来说平衡树的功能远强于堆,能够 \Theta(1) 合并的数据结构不应该能有强功能。
斜堆
这是一种合并均摊 \Theta(\log n) 且其它操作复杂度与二叉堆一致的数据结构。
一个斜堆是满足堆序的二叉树,除此之外没有任何限制。显然斜堆的儿子的子树也是斜堆。
对于两个斜堆的合并。
如果不做任何调整那必然会被卡,于是斜堆做了如下调整:如果递归合并了 r_1 的右儿子,那么合并完后直接交换 r_1 的左右儿子。
时间复杂度分析
令合并次数与 n 同阶,F 为时间复杂度。
使用势能分析,定义一个结点是重的,当且仅当右儿子子树大小大于左儿子子树大小。一个结点轻的话则相反定义。
定义斜堆 T 的右链为从根开始不断走右儿子走到叶子的链。
大小为 n 的斜堆 T 的右链的轻结点数量不会超过 \Theta(\log n) 个,因为每走一次轻结点的右儿子,则子树大小至少折半。
在不做调整的前提下合并,我们记录右链然后再从下往上调整,显然与我们的合并过程等价。且右链上的重结点必定翻转为轻结点(右子树大小增大,左子树不变,它原先就是重的,交换前不改变重的状态,交换之后肯定变成轻),但是轻结点不一定翻转为重结点。
定义 \phi(k) 为第 k 次合并之后的重结点数量。显然 \phi(n) = \Theta(n),\,\phi(0) = \Theta(n)。
设第 k 次合并 T_a 和 T_b。且 T_a 的右链的重结点数量是 x_a 轻结点数量是 y_a。T_b 的右链的重结点数量是 x_b 轻结点数量是 y_b。
则合并一次的代价是 c_k = x_a + x_b + y_a + y_b,并且 \phi(k) \le \phi(k - 1) - x_a - x_b + y_a + y_b。
我们假设每次都达到了最坏情况,即 \phi(k) = \phi(k - 1) - x_a - x_b + y_a + y_b。
令 \omega(k) = \phi(k) - \phi(k - 1) + c_k = y_a + y_b - x_a - x_b + x_a + x_b + y_a + y_b = 2(y_a + y_b) = \Theta(\log n)。固 \sum\limits_{k} w(k) = \Theta(n \log n)。
则 F(n) = \sum c_i = \phi(n) - \phi(0) + \left(\sum\limits_{k} \omega(k)\right) = \Theta(n \log n)。
证毕。
tips:这东西与 Link Cut Tree 的 Access 的复杂度分析非常类似,实际上完全可以互相套用。
左偏树
定义 d(u) 为 u 子树内最浅的叶子深度。
左偏树与斜堆的区别,只是在交换左右儿子的时候,左偏树会判定 d(rs_u) 是否大于 d(ls_u),如果大于了再交换。此时对于右儿子非空的 u 我们有 d(u) = d(rs_u) + 1。
此时可以把合并的均摊去掉,因为 d(rt) \le \lceil \log (n + 1) \rceil,而且每次进右儿子 d 至少减一。
那么左偏树合并的时间复杂度为严格的 \Theta(\log n)。左偏树可以简单使用路径复制,做到可合并持久化。空间复杂度会多一只 \log。
如果基于斜堆,但是每次合并完 \dfrac{1}{2} 的概率交换左右儿子,那么被称为随机堆,时间复杂度正确,期望 \Theta(n \log n)。randomized_heap。
对于上述提到的三种堆,push 就是合并一个大小为 1 的堆,pop 直接合并左右儿子即可。
对于左偏树,delete 需要合并完 x 的左右儿子之后,向上走维护左偏性质。时间复杂度可以证明是 \Theta(\log n),因为无论作为左儿子还是右儿子,每向上走一次更新前的 d 都会增加 1。decrease key 可以基于 delete 直接做,因此 increase key 也是容易的。
斜堆和随机堆也可以做 decrease key,把子树切出来,然后跟原树合并即可。甚至比左偏树方便,因为不需要维护额外信息。
配对堆
这是一种严格 \Theta(1) merge、push 和 top,均摊 \Theta(\log n) 的 pop 的数据结构。
可惜它的 decrease key 的复杂度并不是 \Theta(1)。下界 \Theta(\log \log n),上界 \Theta(2^{\sqrt{\log \log n}})。在 OI 范围内大概可以看作 \Theta(\log \log n)。
这东西实际上思想很简单,证明嘛···学术界对它的 decrease key 都无法给出精确的复杂度。
简单来说,配对堆是一棵满足堆序的有根树,所以它只是满足堆序,而可以不是二叉树。
对于合并,令 r_1,\,r_2 分别是两棵树 T_1,\,T_2 的根且 r_1 \le r_2(不是那就交换)。只是简单粗暴的令 r_2 成为 r_1 的儿子,把 T_2 拼到 T_1 上。merge 和 push 就做完了。
但是这样太偷懒了,于是我们 pop 的时候就很头疼。最简单的想法是学左偏树把根的儿子全部 merge 起来。但是完全可以被卡。
配对堆的调整操作:将相邻的儿子两两配对起来,12 配对、34 配对、56 配对···,配对之后内部自己合并掉。合并完然后以老儿子到新儿子的顺序依次合并。
老儿子指的是对于根来说先合并进来的儿子,新儿子是后来合并进来的儿子。必须按这个顺序合并否则时间复杂度没有保证。
简单来说配对堆一般用左儿子右兄弟的方式存树,或者说链式前向星。那么加入一个儿子就是链表的头插,调整就是递归到链表尾相邻两两合并,然后让末尾合并的结果跟当前相邻的两个合并的结果合并。
对于 decrease key,就是让配对堆维护父指针,然后把修改的点 x 直接剖出来跟整棵树合并。
时间复杂度证明很复杂,这里是原论文链接。
效率似乎还行,不比左偏树差。
二项堆
这是一种严格 \Theta(\log n) 的 merge、pop、decrease key、top(当然 top 维护一个额外变量即可 \Theta(1))以及均摊 \Theta(1) 的 push 的数据结构。是 Fibonacci heap 的基础。
首先定义二项树,二项树是一棵满足堆序的有根树,每棵二项树有一个非负整数等级(Level),而且它的结构是固定的。
1. $0$ 级二项式是单独一个结点。
2. $k$ 级二项树有恰好个儿子 $k - 1$,每个儿子为 $0,\,1,\,2,\,3,\,\dots,,\,k - 1$ 级二项树。
换句话说 $k$ 级二项树的根一定恰好有 $k$ 个儿子。
$k$ 级二项树可以看做是一个 $k - 1$ 级二项树,作为儿子接在另一个 $k - 1$ 级二项树的根下面。$k$ 级二项树恰好有 $2^k$ 个结点,而且深度为 $d$ 的结点数量恰好有 $\dbinom{k}{d}$ 个(这也是这个“二项”的由来,某种意义上来说二项树是一个很优美~~涩情~~的结构)。
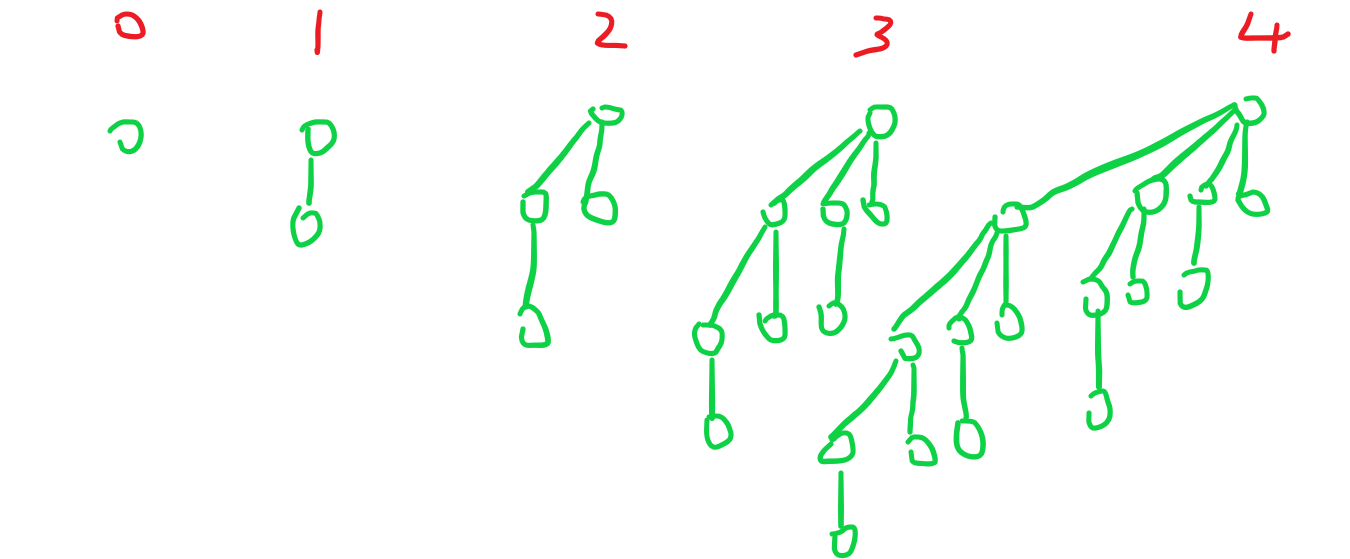
注意这堆树内部都满足堆序。
一个**二项堆**由 $t$ 个二项树组成,每个二项树的等级**两两不同**。你可以把二项堆看作二进制数,有一个 $k$ 级二项树在堆中那么代表第 $k$ 位是 $1$。
定义二项树的合并操作:
设 $T_1$ 和 $T_2$ 分别是待合并的两棵二项树,并且它们的等级相同(等级不相同则不能合并)。
那么合并 $T_1$ 和 $T_2$ 就只是让它们根权值较小的那个根作为新树的根,然后另一棵树直接并在这个根下面当儿子即可。
二项堆的合并就是二进制加法,从低到高对齐,让等级相同的堆合并然后进位即可。
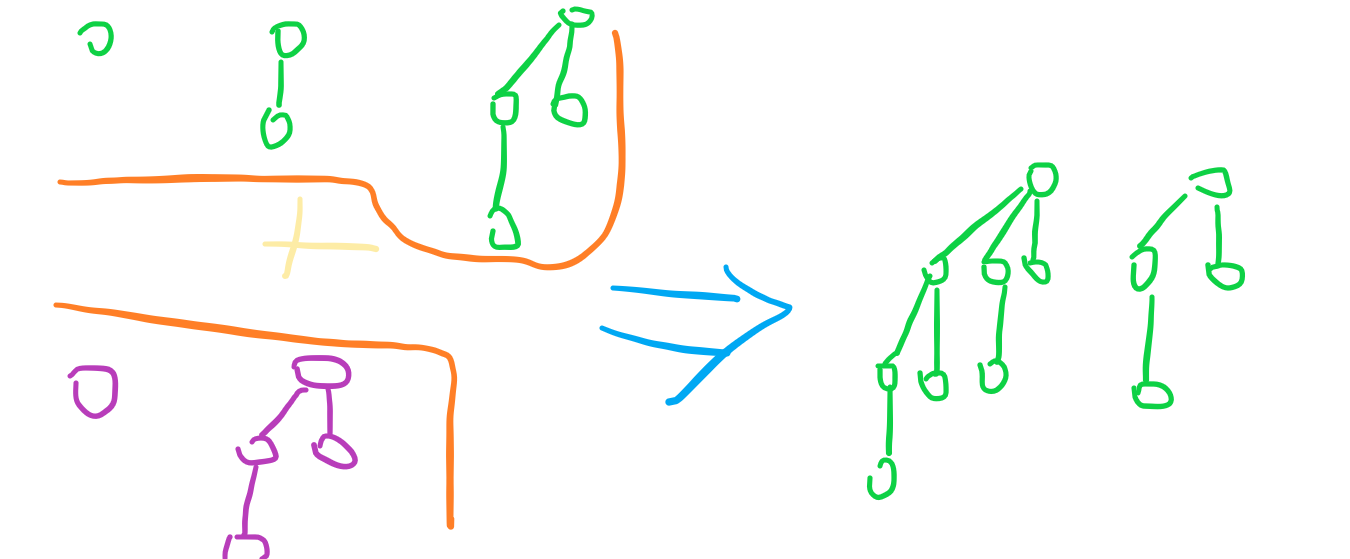
对于 top,由于我们可以把二项堆看作二进制数,那么枚举每一位找根的最小值即可。
对于 pop,那么就是把 top 所在的二项树删去根,显然形成了 $1 \sim k - 1$ 个二项树,把这些二项树看作二项堆然后跟原来的二项堆合并即可。
对于 decrease key,二项树的高度是 $\Theta(\log n)$ 级别的(深度为 $d$ 的点恰好有 $\dbinom{k}{d}$ 个),所以直接进行类似二叉堆的上滤即可。
对于 push 的复杂度,其实是入门级均摊分析。有 $\frac{1}{2}$ 的情况下花费 $1$ 的代价插入好,$\frac{1}{4}$ 的情况下花费 $2$ 的代价插入好,以此类推。$F(n) = n\left(\left(\sum\limits_{i = 1}^{\infty} \dfrac{i}{2^i}\right) + 1\right)$。
而 $\sum\limits_{i = 1}^{\infty} \dfrac{i}{2^i} = \sum\limits_{i=1}^{\infty}\sum\limits_{j=i}^{\infty}\dfrac{1}{2^j} = \sum\limits_{i=1}^{\infty} \dfrac{1}{2^{i - 1}} = 2$。
所以 $F(n) = 3n = \Theta(n)$。
注意这里认为 push 是连续的,中间没有 pop 和 delete 操作。
如果想要带撤销的 $\Theta(1)$ push,那么让二项堆可以至多同时存在两个相同的最低等级的二项树即可,这种技巧称为懒惰删除。本质上是用**斜二进制**代替了二进制。
对比左偏树唯一的优势应该就是均摊 $\Theta(1)$ 的 push,其它感觉不明显。而且代码难度不低。
可以可合并持久化。
### Fibonacci Heap
斐波那契堆是一种 push、merge 严格 $\Theta(1)$,decrease key 均摊 $\Theta(1)$,pop 均摊 $\Theta(\log n)$ 的数据结构。这东西类似懒惰二项树。
这玩意听起来挺吓人,但其实是易学的。
斐波那契堆基于二项堆,并且我们定义一个结点的等级是**它的儿子结点数量**(在二项堆中可以等价定义)。注意斐波那契堆中的树不一定是二项堆,因此需要这样定义。
首先类似二项堆,但是就是直接用个根链表维护所有根,合并就是直接合并根链表(显然严格 $\Theta(1)$)。
其实我们的难点就是 pop 和 decrease key。
如果只有 pop,那我们就是个懒惰二项堆,用个数组存下等级为 $k$ 的所有树,从低到高合并上去即可。
势能是树的数量,每次增加势能 $\Theta(\log n)$ 级别,显然均摊复杂度 $\Theta(\log n)$。
问题就是 decrease key 怎么做。
如果像二项树那样上滤那确实能做,但复杂度是 $\Theta(\log n)$ 的,我们希望能 $\Theta(1)$。
如果直接将子树拆下来塞进根链表里,那是可以被卡的,实际上我们可能会出现度数从 $1$ 到 $\Theta(\sqrt n)$ 的结点,让我们的复杂度退化为根号复杂度,这是我们不希望看到的。
于是斐波那契堆就有了这种操作:
- 给每个点给一个布尔的标记,初始都是 `false`。
我们定义**级联剪切:**
- 如果要拆出去一个子树,且子树的父亲标记是 `false`,那么就把子树的父亲标记置为 `true` 并退出。
- 如果子树的父亲标记是 `true`,那么将递归对父亲级联剪切。
注意一个点一旦成为根,那么就要置这个点的标记为 `false`。
实际上我们就是观察一个结点被摘除的儿子是否大于 $1$ 个,如果大于 $1$ 个就给它也摘下去。
可以证明,引入级联剪切并不会破坏 pop 的均摊分析,并且 decrease key 的复杂度是均摊 $\Theta(1)$ 的。
**时间复杂度?**
容易感性理解,但证明还是相对麻烦的,留给读者。
在《算法导论》上可以查阅到关于这个数据结构的讲解和严谨证明。跟 OI 关系不大所以就略过了(视情况可能会增加)。
斐波那契堆虽然实现不难,但常数极大,一般在 OI 中的应用很少。
困难持久化,因为基于均摊。
### Rank Paring Heap
~~人品堆。~~
UT 老师说,大量类似配对堆的 self-adjusting 的可并堆,在 $\Theta(\log n)$ 的 pop 的前提下 decrease key 的复杂度都没有低于 $\Theta(\log \log n)$。这就是一个叹息之墙。
配对堆的 decrease key 复杂度不是 $\Theta(1)$ 的,我们希望能继续优化它。
一种称为 Rank Paring Heap 的配对堆变体,能做到与斐波那契堆相同的时间复杂度。
RP-Heap 是由若干**半树**组成的。
- $\text{half-ordered}$:每个结点的权值都小于等于左子树任意结点的权值。
- **半树:** 一棵二叉树,每个结点都满足 $\text{half-ordered}$。并且根结点没有右儿子。
不妨将根结点左儿子子树是满二叉树的半树,称为满半树。显然任意两个满半树合并起来仍然是满半树。
钦定单个结点是满半树,并且定义它的 **rank** 是 $0$,rank 是一个非负整数,代表一个半树的**等级**。
对于 rank 相同的半树,可以进行 fair-link 形成一个 rank 是它们的 rank 加一的半树。
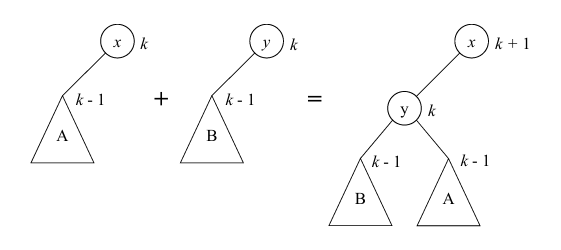
满半树跟二项树等价,实际上一棵满半树就是二项树的左儿子右兄弟表示,如果把“右兄弟”当作右儿子的话。如果没有 decrease key,那么 RP-Heap 跟懒惰二项堆(不带级联剪切的斐波那契堆)几乎完全一致。
用根链表维护每个满半树,pop 就是递归右链切除,合并就是直接接根链表。
同时跟二项堆一样 pop 之后 self-adjust,把根链表里所有 rank 相同的半树合并起来。
但有一点不一样的是,二项堆会把合并出来的新树继续进行合并,而 RP-Heap 只是把每个固定的等级的半树**两两配对**进行合并,合并出来的新树**不再参与合并。**
比如当前等级 $r$ 有 $k$ 个半树,那么就会产生 $\lfloor\frac{k}{2}\rfloor$ 个 $r + 1$ 等级的半树,以及当 $k$ 为奇数的时候还剩下一个 $r$ 等级的半树。这就是为什么它是一种配对堆变体的原因。
这东西可以均摊到 $\Theta(\log n)$ 的 pop 之外其它操作均为 $\Theta(1)$,当然前提是不带 decrease key 和 delete。
还有如何做 decrease key。
定义 $\Delta \text{rank}(u) = \text{rank}(\text{fa}_u) - \text{rank}(u)$,其中 $\text{fa}_u$ 是 $u$ 的父亲。
令两个儿子的 $\Delta \text{rank}$ 分别为 $x,\,y$ 的结点称为 $(x,\,y)$ 结点。如果没有右儿子,那么就是 $(x,\,-1)$。
在没有 decrease key 的时候,RP-Heap 内部要么是 $(1,\,1)$ 结点要么是 $(1,\,-1)$ 结点。
我们必须放宽这个限制以支持 $\Theta(1)$ 的 decrease key。
引入两种 rank rule:
- Type $1$:每个根是 $(1,\,-1)$ 结点,每个非根结点要么是 $(1,\,1)$ 结点,要么是 $(0,\,?)$ 结点。
- Type $2$:每个根是 $(1,\,-1)$ 结点,每个非根结点要么是 $(1,\,1)$ 结点,要么是 $(1,\,2)$ 结点,要么是 $(0,\,?)$ 结点。
如果原树满足这两个 rank rule 的任意一个,那么 rank 的最大值是 $\Theta(\log n)$ 级别的(前者 $\log_2 n$ 后者 $\log_{\phi} n$)。
注意 $?$ 可以代表任意正整数。
考虑 decrease key 一个结点 $u$。如果 $u$ 是根结点,直接退。
否则令 $u$ 的 rank 变为 $\text{rank}(\text{ls}_u) + 1$,然后从 $u$ 的祖先链从下到上,依次判定是否满足 rank rule,如果不满足那么就减少 rank 直到满足 rank rule。
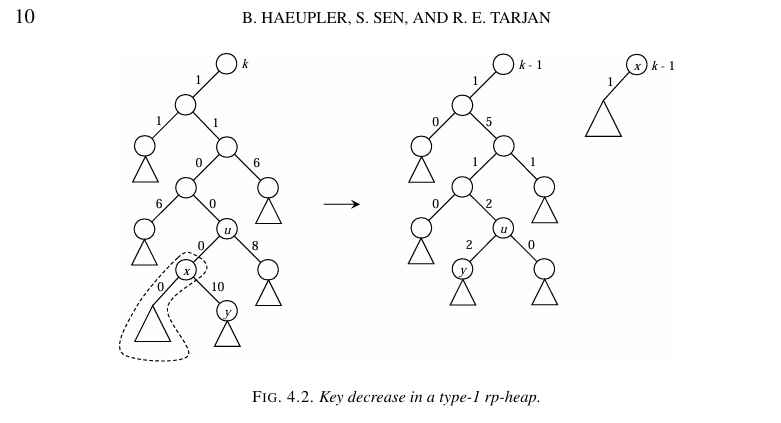
这里不管使用 Type $1$ 还是 Type $2$,decrease key 的复杂度都可以分析到 $\Theta(1)$。似乎 Type $2$ 的常数一般会更小。
整体复杂度分析很复杂,不过 pop 的分析可以套用 Splay 的 zig-zag。
### 斜二项堆
这东西打算延后。
lxl 的 WC2024 讲义上说是,除了 decrease key 外做到 Brodal Queue 复杂度的数据结构(不基于均摊)。
主要资料实在过少。
### 基数堆
目前看到的中文资料是[这篇博客](https://www.luogu.com.cn/article/98ynmyy9)。
一种基于值域的堆,做到 $\Theta(\log v)$ 的 push、pop。以及 $\Theta(1)$ 的 top 和均摊 $\Theta(1)$ 的 decrease key。
可以被加强到 $\Theta(\frac{\log v}{\log \log v})$ 或 $\Theta(\sqrt{\log v})$ 的 push 和 pop。
基于值域,基数堆维护了 $\Theta(\log v)$ 个桶,每个桶用链表维护。初始每个桶的大小分别是 $1,\,1,\,2,\,4,\,8,\,\dots$。存的区间是 $[0,\,0],\,[1,\,1],\,[2,\,3],\,[4,\,7],\,[8,\,15],\,\dots$。注意后面桶维护的区间可能会改变。
令第 $i$ 个桶的右端点是 $r_i$,大小是 $s_i$。
insert 很简单,设插入 $x$,枚举每个桶,找到包含 $x$ 的那个桶插进那个桶链表的末尾即可。
decrease key 就直接在原来桶的基础上向前枚举前移,因为至多减小 $\log v$ 次势能,总的复杂度是 $n \log v$ 而非 $m \log v$($m$ 是 decrease key 的次数)。换句话说 decrease key 的复杂度不会超过插入的复杂度。用它来优化 dijkstra 的复杂度会是 $\Theta(n \log v + m)$ 的。
难做的是 pop,先从小到大找到第一个非空桶,同时暴力找到这个桶中的最小值。复杂度可能是 $\Theta(n)$ 的,所以我们需要 self-adjust。
如果我们找到的最小值在 $1$ 号桶,那直接返回这个桶里面任意一个元素。
否则设在 $k$ 号桶,找到的最小值为 $x$。
引入 distribute 操作,让 $r_0 = x - 1,\,r_1 = x$ 并且 $r_i \leftarrow \min(r_i,\,r_{i - 1} + s_i)$。
注意到要么桶的形态不变复杂度为 $\Theta(1)$,要么所有桶的标号减少至少 $1$,总时间复杂度不超过 $\Theta(n \log v)$,由于要寻找非空桶均摊复杂度 $\Theta(\log v)$。
如果要优化 dijkstra 算法,那么得到时间复杂度 $\Theta(n \log v + m)$,实践中也非常优秀。
**继续的优化:**
实际上基数堆可以被加强,做到 $\Theta(\frac{\log v}{\log \log v})$ 或 $\Theta(\sqrt{\log v})$ 的 push 和 pop。
这里选择延后更新,需要者可以去看给出的链接。
### 可并堆的代替实现
pbds 库中给出了一些可并堆的实现。
需要包含头文件:
```cpp
#include <ext/pb_ds/priority_queue.hpp>
```
并引用 `__gun_pbds` 命名空间。
提供了五种可用的优先队列,即 `binary_heap_tag`、`pairing_heap_tag`、`binomial_heap_tag`、`rc_binomial_heap_tag`、`binary_heap_tag` 和 `thin_heap_tag`,分别是二叉堆、配对堆、二项堆、冗余计数二项堆和一种 tarjan 发明的除了合并外跟斐波那契堆堆复杂度一样的堆。
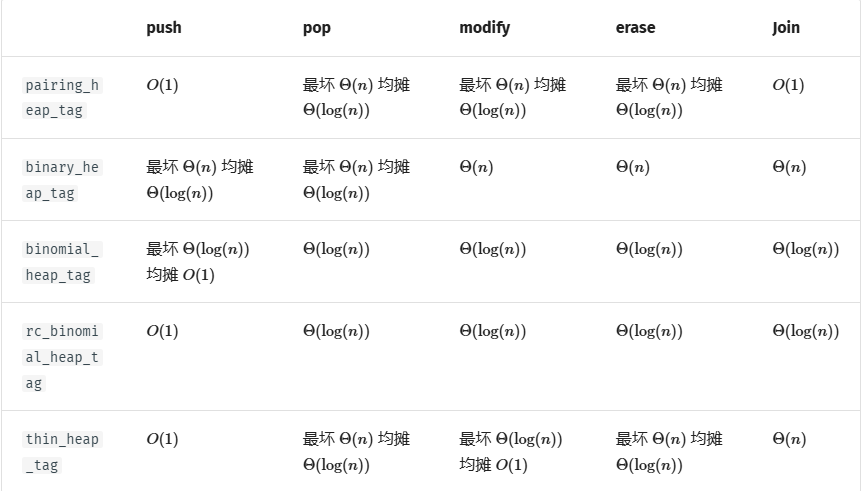
来源:OI-Wiki。
示例:
```cpp
__gnu_pbds::priority_queue<int, greater<int>, __gnu_pbds::pairing_heap_tag> q;
```
创建一个小根配对堆。
### 一些应用和持久化
关于持久化,带均摊的数据结构一般困难完全持久化,因为我们可能多次回退到耗时高的一个版本,导致势能分析不再成立。
一般来说,OI 中的持久化可并堆用左偏树实现。
**模板:** [P3377](https://www.luogu.com.cn/problem/P3377),很平凡的模板。
可并堆的一个作用是用来优化凸包的闵可夫斯基和,以及 Slope Trick 等等凸函数合并。
例题:[ABC275H](https://www.luogu.com.cn/problem/AT_abc275_h),[P6943](https://www.luogu.com.cn/problem/P6943)。
持久化可并堆的一个典中典应用是优化 $k$ 短路:[P2483](https://www.luogu.com.cn/problem/P2483)。
持久化可并堆的一个应用是套上线段树。
不过实际上应用并不广就是了。