P3640 [APIO2013] 出题人
题目描述
当今世界上各类程序设计竞赛层出不穷。而设计一场好比赛绝非易事,比如给题目设计测试数据就是一项挑战。一组好的测试数据需要对不同的程序有区分度:满足所有要求的程序自然应该得到满分,而那些貌似正确的程序则会在某些特殊数据上出错。
在本题中,你在比赛中的角色反转啦!作为一名久经百战的程序员,你将帮助 Happy Programmer Contest 的命题委员会设计这次比赛的测试数据。本次比赛命题委员会选择了两个图论问题,分为 $8$ 个子任务。委员会写了一些貌似可以解决这些子任务的代码。在给任务设计数据的时候,命题委员会期望其中的一些源程序能够得到满分,而另外的一些则只能得到 $0$ 分或者少许的部分分。现在你将会获得这些源程序(C, C++, Pascal 版本)。对于每个子任务,你需要去产生一组数据 $X$ 使得它能将该任务给定的 $2$ 种源程序 $A$ 和 $B$ 区分开来。更具体地说,生成的数据必须满足如下两个条件:
输入 $X$ 对于源程序 $A$ 一定不会出现超出时间限制(TLE)的问题。
输入 $X$ 一定会导致源程序 $B$ 产生超出时间限制的问题。
此外,命题委员喜欢较小规模的测试数据,希望测试数据最好能够包含不超过 $T$ 个整数。
本题中只关心源程序 $A$ 和 $B$ 是否超时,不关心是否结果正确。
命题委员会选择了单源最短路(SSSP)以及一个被称之为神秘问题(Mystery)的两个图论问题来作为比赛的题目。我们将命题委员会完成的伪代码列在了附录中,而具体的 C、C++ 和 Pascal 源程序被我们放在了下发的文件当中。
### 子任务
参见下表。表中每一行描述了一个子任务。其中前六个子任务与单源最短路相关,子任务 7,8 与神秘问题相关。每个任务所占分数见下表。
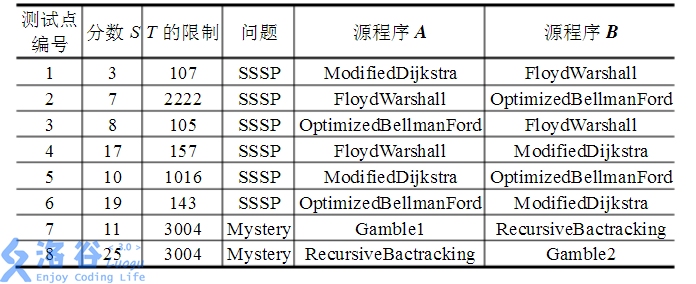
对于每个子任务,你的程序给出的输入 $X$ 需要能够将源程序 $A$ 和 $B$ 区分开来,这有这样你才能够得到相应的分数。具体说来,你的分数将由输入 $X$ 中数的个数决定。假设 $X$ 中包含了 $F$ 个整数,子任务的满分为 $S,T$ 是该任务的目标大小,则该测试点的分数将由下式给出:
$$S \times \min\{T / F, 1\}$$
也就是说,如果你的测试数据 $X$ 中含有不超过 $T$ 个整数,则你将得到该任务的全部得分。
你需要把你的 $8$ 个测试数据命名为 `1.txt` ~ `8.txt`。对于每个子任务 $X$,评测系统将根据如下步骤来确定你将会得到多少分:
- 如果未提交数据,则不得分;
- 若数据不满足输入格式要求,则不得分;
- 对源程序 $A$ 运行输入,若发生超时现象,则不得分;
- 对源程序 $B$ 运行输入,若发生超时现象,则按照前文所述的公式给出该测试点的分数。
题目提供的所有源代码均会维护一个计数器来统计程序的操作次数。在源程序的运行过程中,当该计数器超过了 $10^6$ 次时,那么我们认为程序运行超时。
### 问题 1:单源最短路(SSSP)
给定一个带权有向图 $G$,以及 $G$ 中的两个节点 $s$ 与 $t$,令 $p(s, t)$ 为 $G$ 中从 $s$ 至 $t$ 的最短路长度。如果 $s$ 与 $t$ 不连通,则认为 $p(s, t)=10^9$。在本题中,输入为图 $G$ 以及 $Q$ 个询问 $(s_1, t_1), (s_2, t_2), \dots, (s_Q, t_Q)$ 。输出则是对这 $Q$ 个询问的相应输出 $p(s_1, t_1), p(s_2 , t_2), \cdots, p(s_Q, t_Q)$。
### 问题 2:神秘问题
给定一个包含 $V$ 个节点 $E$ 条边的无向图 $G$,要求将所有的节点进行编号(编号范围为 $[0, X-1]$),使得所有直接相连的节点均有不同的编号。找出符合题意的最小的 $X$。
输入格式
### 问题 1
输入数据包含两部分,其中第一部分使用邻接表来描述带权有向图 $G$。第二部分则描述对 $G$ 的最短路径的查询。
数据第一部分的第一行包含一个整数 $V$,表示 $G$ 中点的个数,所有点的编号为 $0, 1, \cdots, V - 1$。
接下来 $V$ 行,每行描述一个点的所有边。行中的第一个整数 $n_i$ 描述了节点 $i$ 的出边数量,接下来有 $n_i$ 个整数对 $(j, w)$ 表示有一条从 $i$ 到 $j$,边权为 $w$ 的边。
数据第二部分的第一行包含一个整数 $Q$,表示询问的组数。
接下来 $Q$ 行,第 $k$ 行包含两个整数 $s_k, t_k$,为该询问对应的起点与终点位置。
同一行中任意两个相邻的整数均需要至少一个空格将他们分开。除此之外,数据还需满足如下条件:
- $0 < V \leq 300$,$n_i$ 是一个非负整数,$0 \leq j < V$,$\lvert w \rvert < 10^6$,$0 \leq \sum\limits_{i = 0}^{V-1} n_i \leq 5000$,$0 < Q \leq 10$,$0 \leq s_k < V, 0 \leq t_k < V$;
- 图中没有负权圈。
### 问题 2
输入数据的第一行包含两个整数 $V$ 和 $E$。
接下来 $E$ 行,每行两个整数 $a, b$,表示 $a$ 与 $b$ 在 $G$ 中直接相连。此外,输入数据应满足如下限制条件:
- $70 < V < 1000$,$1500 < E < 10^6$;
- 对于所有的边 $(a, b)$,有 $a \neq b, 0 \leq a < V, 0 \leq b < V$,不会重复描述一条边。
输出格式
### 问题 1
程序将会输出 $Q$ 行,每行一个整数,表示对应的 $p(s_k , t_k)$。而在输出的最后,所有提供的程序都会给出计数器对此输入的数值。
### 问题 2
程序将在第一行输出 $X$,即最小的编号范围,接下来在第二行中给出 $V$ 个整数,依次描述节点 $0$ 至 $V - 1$ 的编号。在输出的最后,所有提供的程序都会给出计数器对此输入的数值。
说明/提示
**源代码见附件**。
### 附录:伪代码
接下来是我们提供的所有程序的伪代码;变量 counter 近似描述出了程序的运行时间。评测时将会使用这些伪代码的 C++ 版本来进行评测。
FloydWarshall
```cpp
// pre-condition: the graph is stored in an adjacency matrix M
counter = 0
for k = 0 to V-1
for i = 0 to V-1
for j = 0 to V-1
increase counter by 1;
M[i][j] = min(M[i][j], M[i][k] + M[k][j]);
for each query p(s,t)
output M[s][t];
```
OptimizedBellmanFord
```cpp
// pre-condition: the graph is stored in an adjacency list L
counter = 0
for each query p(s,t);
dist[s] = 0; // s is the source vertex
loop V-1 times
change = false;
for each edge (u,v) in L
increase counter by 1;
if dist[u] + weight(u,v) < dist[v]
dist[v] = dist[u] + weight(u,v);
change = true;
if change is false // this is the ’optimized’ Bellman Ford
break from the outermost loop;
output dist[t];
```
ModifiedDijkstra
```cpp
// pre-condition: the graph is stored in an adjacency list L
counter = 0;
for each query p(s,t)
dist[s] = 0;
pq.push(pair(0, s)); // pq is a priority queue
while pq is not empty
increase counter by 1;
(d, u) = the top element of pq;
remove the top element from pq;
if (d == dist[u])
for each edge (u,v) in L
if (dist[u] + weight(u,v) ) < dist[v]
dist[v] = dist[u] + weight(u,v);
insert pair (dist[v], v) into the pq;
output dist[t];
```
Gamble1
```cpp
Sets X = V;
labels vertex i in [0..V-1] with i;
Sets counter = 0; // will never get TLE
```
Gamble2
```cpp
Sets X = V;
labels vertex i in [0..V-1] with i;
Sets counter = 1000001; // force this to get TLE
```
RecursiveBacktracking
```cpp
This algorithm tries X from 2 to V one by one and stops at the first valid X.
For each X, the backtracking routine label vertex 0 with 0, then for each vertex u that has been assigned a label, the backtracking routine tries to assign
the smallest possible label up to label X-1 to its neighbor v, and backtracks if necessary.
// Please check RecursiveBacktracking.cpp/pas to see
// the exact lines where the iteration counter is increased by 1
```
感谢zhouyonglong修改spj